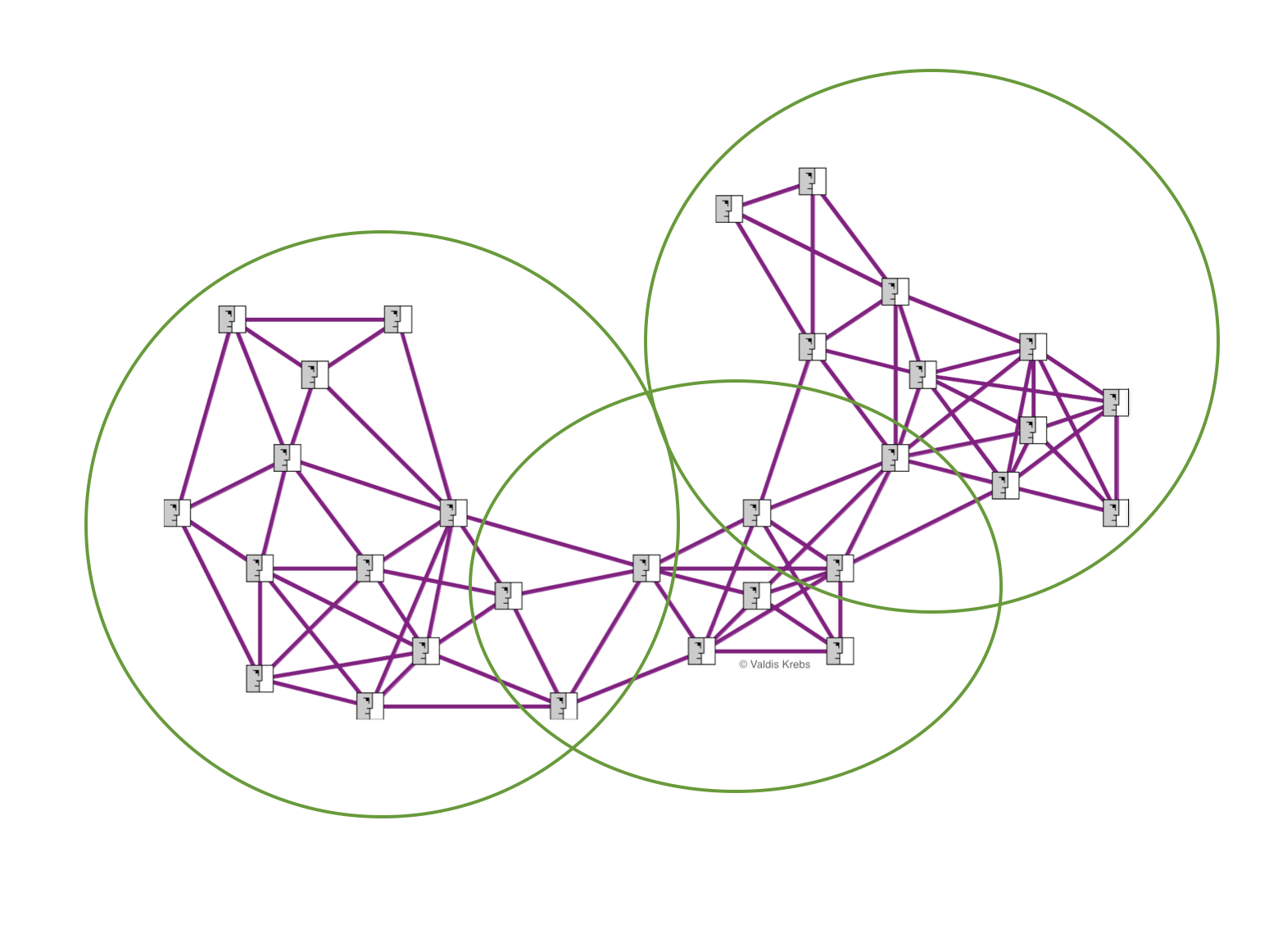
It is funny, when we think about networks, we think about groups, communities, systems, and other complex collections of interacting entities. Yet, the most popular social network metrics are “individual centralities”! Who is the most connected? Who is the best connected? Who is the hub? Who is the influencer? Who spans the most structural holes […]
Back in June 2015, we began the Fragments of Impact programme, partnering with UNDP, to explore how to use SenseMaker® in monitoring and evaluation. This week we’re back in Istanbul, with all the various participants to teach and explore the data and what to do next – in terms of interventions, in terms of monitoring […]
Tag clouds were a popular web visualization fad about 3 years ago. Wordle.net provides a really easy way for you to make and share your own. But rarely is seeing the most frequently-used words in a piece of text very instructive. Today I figured out how to compare two wordles using python. The difference between […]
I’ve spent the first part of this week (and the first few days of my guest-blogging – which I’d not put in the diary) at a fascinating event with Dave. There’s nothing quite like a room of diverse perspectives and fierce minds for stimulating your thinking. As part of the after-dinner entertainment on Monday, Dave […]
One of the hazards of doing research with a broad focus is getting lost in all the information out there. One of the pleasures is just wandering around the internet looking for stuff. Data overload is one of the main reasons I was so grateful to come across the Cynefin framework in late 2006. Apart […]
A big thanks to David Williams who has been the guest blogger since 30th August. Wendy Elford from Canberra here. This first blog in the next stint will skip any real detail on personal history but I will say that both my job roles and interests place me at a halfway point between art and […]
The Cynefin Company (formerly known as Cognitive Edge) was founded in 2005 by Dave Snowden. We believe in praxis and focus on building methods, tools and capability that apply the wisdom from Complex Adaptive Systems theory and other scientific disciplines in social systems. We are the world leader in developing management approaches (in society, government and industry) that empower organisations to absorb uncertainty, detect weak signals to enable sense-making in complex systems, act on the rich data, create resilience and, ultimately, thrive in a complex world.
Cognitive Edge (USA), Inc.1000 N. WEST ST STE 1200 WILMINGTON DE 19801 USA
COOKIES ON OUR WEBSITE
We use cookies to ensure that we give you the best experience on our website. If you continue without changing your settings, we'll assume that you are happy to receive all cookies on The Cynefin Co website. However, if you would like to, you can change your cookie settings at any time. To find out more, please view our cookies policy.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.